Schritt 1 — Upload
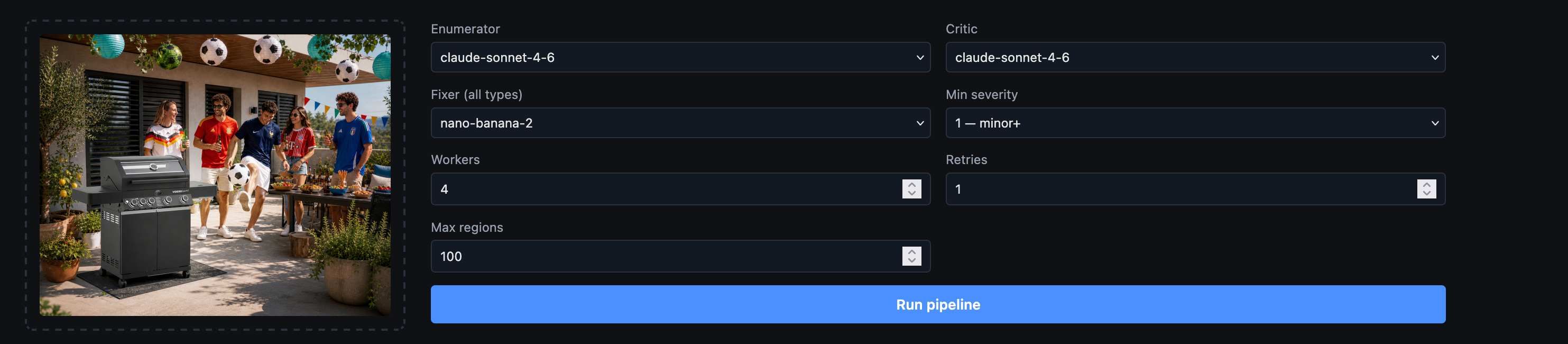
Schritt 2 — Erkennen

Schritt 3 — Auswählen
Schritt 4 — Prüfen

- Brillengläser zeigen keine konsistente Umgebungsreflexion — linkes Glas hat einen vagen hellen Fleck, rechtes wirkt flach
- Hauttextur auf Stirn und Wangen zu glatt und leicht wächsern — keine Porenstruktur erkennbar
- Afro-Locken zeigen charakteristische KI-Textur — einzelne Strähnen verschmelzen und verlieren Definition
- Bartstoppelmuster etwas zu gleichmäßig und symmetrisch
Schritt 4 — Prüfen
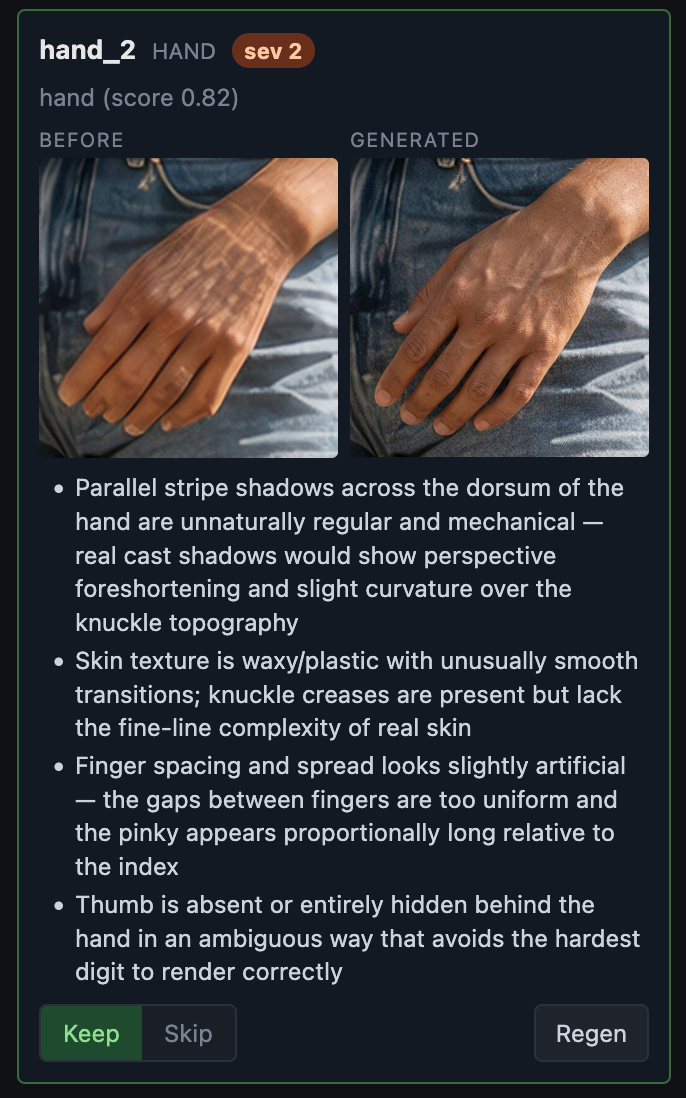
- Parallele Schattenstreifen auf dem Handrücken unnatürlich regelmäßig — echte Schatten zeigen perspektivische Verkürzung
- Hauttextur wächsern und plastisch; Knöchelfalten vorhanden, aber ohne feine Linienstruktur
- Fingerabstände künstlich gleichmäßig — kleiner Finger unverhältnismäßig lang im Vergleich zum Zeigefinger
- Daumen fehlt oder versteckt sich hinter der Hand — vermeidet den schwierigsten Finger für KI
Ergebnis
